

[APPLICATION KIOXIA] A mesure que les charges de travail de l’intelligence artificielle (IA) se complexifient, l'attention se porte souvent sur les processeurs graphiques et les algorithmes. Mais le stockage joue un rôle bien plus important qu'on ne le pense. De l'ingestion des données à l'inférence en temps réel et à la sauvegarde des modifications, les performances de stockage ont un impact direct sur l'efficacité, l'évolutivité et la consommation énergétique. Dans cet article Kioxia explore les principaux défis du pipeline d'IA et explique comment les technologies SSD, notamment les disques PCIe 5.0 et la solution AiSAQ de Kioxia, sont conçues pour répondre à ces exigences en constante évolution.
 Auteur : Frederik Haak
Auteur : Frederik Haak
General Manager SSD Business Unit
KIOXIA Europe GmbH
L’intelligence artificielle (IA) et l’apprentissage automatique (ML) ont récemment connu des avancées significatives, portées par des algorithmes avancés et l’amélioration rapide des performances des unités de traitement graphique (GPU).
Ces progrès, combinés à d’immenses ensembles de données d’entraînement, ont modifié les besoins en stockage de données, entraînant une demande croissante en matière de systèmes spécialisés à forte capacité et haute performance.
Si le maintien d’une efficacité d’entraînement élevée et d’une infrastructure à base de GPU pleinement exploitée constitue un défi majeur, les exigences en matière de stockage de données par IA sont plus larges. Le cycle de traitement des données par l’IA dans les serveurs d’entreprise modernes comprend plusieurs étapes critiques du point de vue du stockage : l’ingestion de données, la préparation des données, l’entraînement de l’IA et l’inférence d’IA.
Les grands modèles de langage (LLM) peuvent également intégrer un ancrage via la génération augmentée de récupération (RAG).
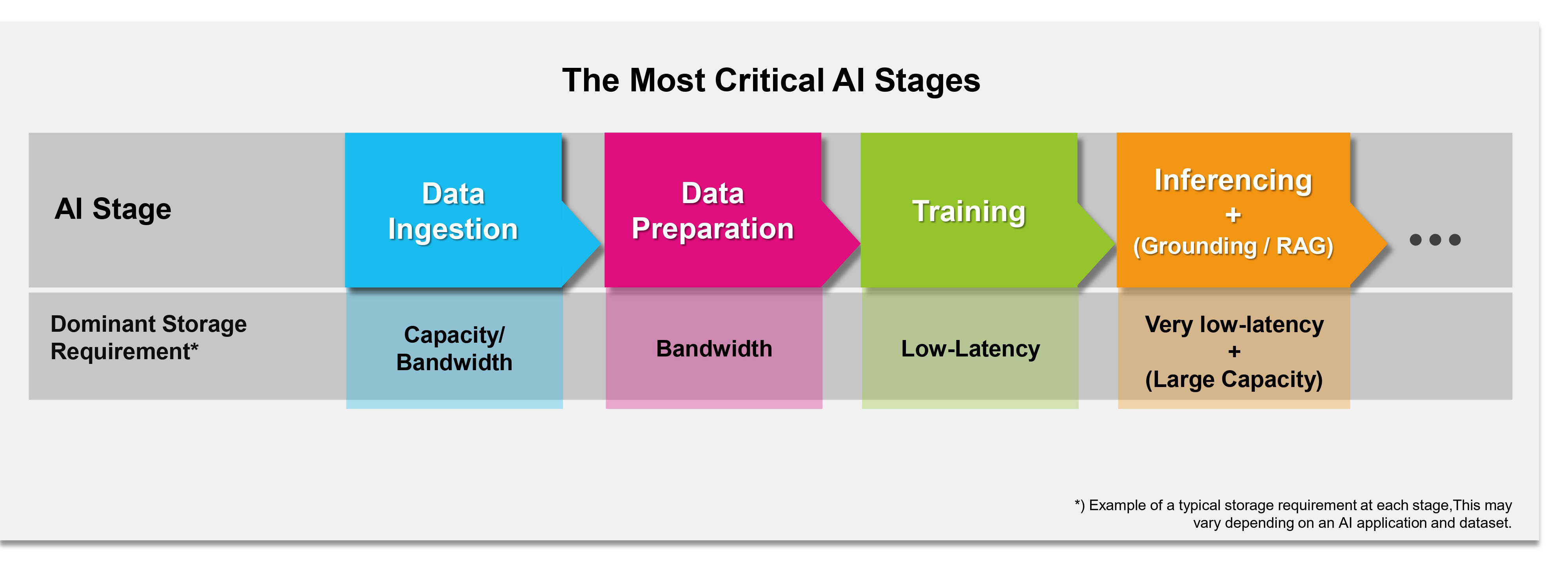
Les étapes critiques du traitement des données par l’IA du point de vue du stockage.
L’ingestion des données
C’est l’une des premières étapes, la collecte de fichiers provenant de différentes sources dans un seul lieu de stockage. Cela peut impliquer le transfert de données depuis des sources telles que les bases de données, le contenu utilisateur et les capteurs vers un stockage centralisé.
La charge de travail nécessite une capacité importante, les applications d’IA/ML générant des opérations à haut débit et englobant une large gamme de charges de stockage. Les charges de travail varient : certaines nécessitant de nombreuses écritures séquentielles (grands lots), tandis que d’autres peuvent aboutir à un schéma d’accès aléatoire (streaming, temps réel, petits blocs entrelacés). Les données d’entrée doivent souvent être stockées rapidement.
La préparation des données et la formation du modèle
A cette étape, les données sont nettoyées, transformées et intégrées en un ensemble de données structuré et potentiellement enrichi pour l’entraînement et l’évaluation du modèle. Cela implique le nettoyage, le filtrage, la normalisation, l’augmentation et l’étiquetage. La charge de travail des entrées/sorties peut être assez intensive à ce niveau en raison de l’accès fréquent aux données, des modifications et des réécritures. Une bande passante d’écriture élevée est ici très avantageuse.
Cette phase passe d’une consommation intensive de données à une sensibilité plus tardive et reste l’une des plus exigeantes en matière de stockage. La charge de travail de stockage dépend fortement du modèle, du jeu de données et du processus de formation.
L’entraînement de l’IA nécessite généralement un débit élevé de données pour charger de grands ensembles de données et des points de contrôle fréquents. Bien qu’un haut débit soit crucial, un stockage à faible latence permet d’améliorer l’efficacité globale. Cela réduit le temps d’accès et de chargement des blocs de données, ce qui est important pour un accès fréquent pendant l’entraînement, ainsi que le temps de contrôle, et par conséquent, le temps d’inactivité du GPU.
La bande passante de lecture requise varie considérablement en fonction de la subordination au temps de calcul du modèle et de la taille de l’entrée, comme le montre la comparaison des demandes pour différents modèles d’image (par exemple, ResNet-50 vs. 3D U-Net).
Une solution bien conçue doit fournir une performance de lecture fiable avec la latence requise pour une utilisation optimale du GPU.
L’inférence un point crucial
Cette étape se produit après l’entraînement, en utilisant le modèle pour prédire de nouvelles données. Elle se caractérise par des opérations à forte intensité de lecture nécessitant des latences stables et très faibles. L’inférence en temps réel exige un accès aux données à grande vitesse constant.
Le stockage d’IA joue ici un rôle important dans la gestion des charges d’inférence. A mesure que les charges d’inférence évoluent, le système doit s’adapter rapidement en chargeant les modèles d’IA du stockage vers la mémoire GPU, ce qui nécessite une latence et une bande passante suffisantes pour éviter les problèmes et la sous-utilisation du GPU.
Le LLM Grounding (RAG, retrieval augmented generation pour génération augmentée de récupération ou génération à enrichissement contextuel) est un processus qui utilise de grands modèles de langage (LLM) avec des connaissances externes. Un ancrage efficace utilisant l’approche RAG nécessite une réponse de stockage à faible latence pour la récupération en temps réel des informations ou documents pertinents.
Cela implique souvent l’accès à des morceaux de données spécifiques comme les embeddings (*) rendant la performance de lecture aléatoire importante. La vectorisation des données propriétaires pour RAG crée des embeddings qui multiplient la taille des données.
En raison de ces exigences d’accès, la performance de lecture aléatoire peut souvent devenir importante pour respecter les délais de réponse attendus lors de la génération de réponses aux utilisateurs finaux.
Quelle technologie SSD utiliser ?
La cellule à triple niveau (TLC) est la technologie Flash dominante, complétée par la cellule à quadruple niveau (QLC). La gamme BiCS FLASH de Kioxia intègre ces deux technologies. Bien que la QLC soit utilisée lorsque des capacités extrêmement importantes sont requises (surpérieur à 60 To), la TLC reste présente pour des cas nécessitant des latences courtes, de hautes performances et une autonomie raisonnablement élevée.
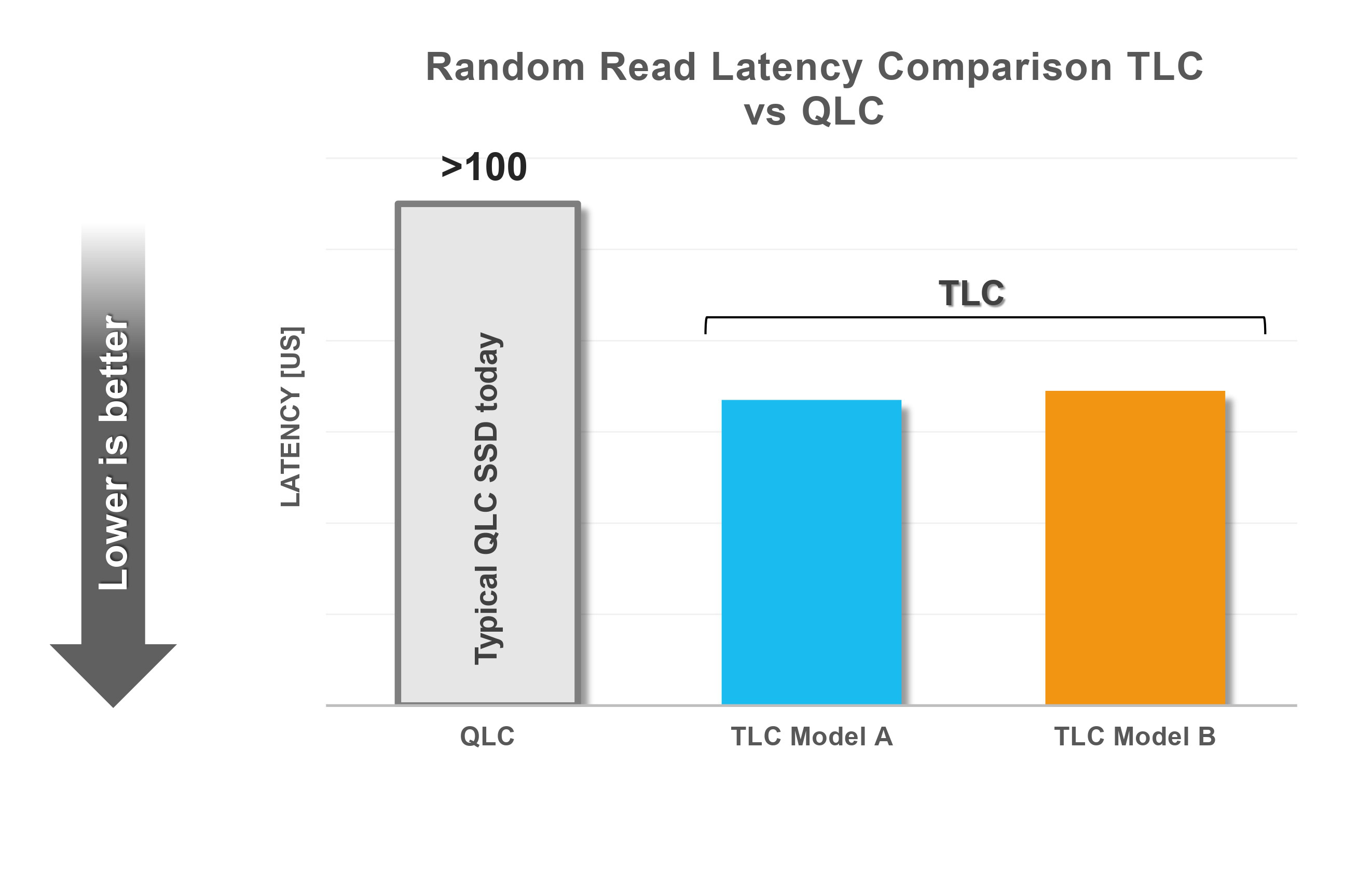
Alors que les disques QLC répondent aux besoins nécessitant des capacités extrêmement importantes, les disques TLC jouent un rôle important dans les cas d’utilisation nécessitant une faible latence Les disques QLC existants ont des latences plus élevées que les TLC équivalents.
Ces solutions peuvent nécessiter une mémoire de classe de stockage (SCM) coûteuse pour la mise en cache afin d’améliorer l’endurance et les performances, ce qui pourrait augmenter les coûts globaux de stockage. Le choix de la technologie SSD nécessite donc une attention particulière à ces facteurs.
Pour les étapes d’ingestion et de préparation des données, les disques SSD sont considérés comme un choix optimal de support de stockage en raison de leurs grandes capacités et de leur aptitude à gérer efficacement des charges de travail nécessitant une grande bande passante.
En raison de ses vitesses de lecture et d’écriture rapides, la DRAM est généralement utilisée pour les données qui doivent être consultées rapidement et fréquemment, comme les ensembles de données de travail lors de l’entraînement du modèle, là où les paramètres sont constamment mis à jour, ou pour maintenir les poids d’un réseau de neurones lors de l’inférence.
Cependant, certains modèles d’IA peuvent déjà dépasser la capacité de DRAM GPU disponible localement. Ainsi, les données doivent être stockées sur le support le plus rapide suivant, comme les disques SSD NVM Express (NVMe) (**).
L’efficacité énergétique des systèmes de stockage de données par IA peut aussi avoir un impact sur la capacité globale d’entraînement. Les recherches montrent que le stockage et le prétraitement peuvent consommer davantage d’énergie que les GPU dans certains cas, limitant potentiellement la capacité d’entraînement en raison de budgets énergétiques fixes des centres de données.
Par conséquent, le stockage et l’efficacité des SSD doivent être pris en compte lors de la conception de systèmes d’IA. Kioxia se concentre à ce niveau sur l’optimisation de l’efficacité énergétique de ses SSD, maintenant une consommation modérée même avec des capacités PCIe 5.0 hautes performances, libérant ainsi de l’énergie pour les GPU.
Dans le cas de l’inférence LLM, l’approche RAG nécessitait traditionnellement une DRAM importante (par exemple, pour les algorithmes dits HNSW (Hierarchical Navigable Small World) rendant alors son évolution coûteuse et difficile.
Les solutions fondées sur des disques SSD, telles que celles développées sur Microsoft DiskANN et Kioxia AiSAQ (ANNS tout-en-stockage avec quantification des produits), offrent une alternative rentable et évolutive aux solutions coûteuses basées sur DRAM en transférant partiellement ou entièrement les bases de données vectorielles vers des SSD.
La technolofgie AiSAQ vise une empreinte de mémoire DRAM minimale sans dégradation significative des performances.
Aller vers un contrôle de l’IA
Le contrôle de l’IA est crucial en raison de la nature gourmande en ressources et de la durée prolongée de la formation des modèles d’IA modernes, qui peut prendre des mois.
Les défaillances sont fréquentes dans des infrastructures complexes avec de longs cycles d’entraînement. Les études montrent des taux de défaillance significatifs. Par exemple, jusqu’à 43,4 % pour les tâches les plus gourmandes en ressources, jusqu’à sept par semaine avec 128 GPU (***).
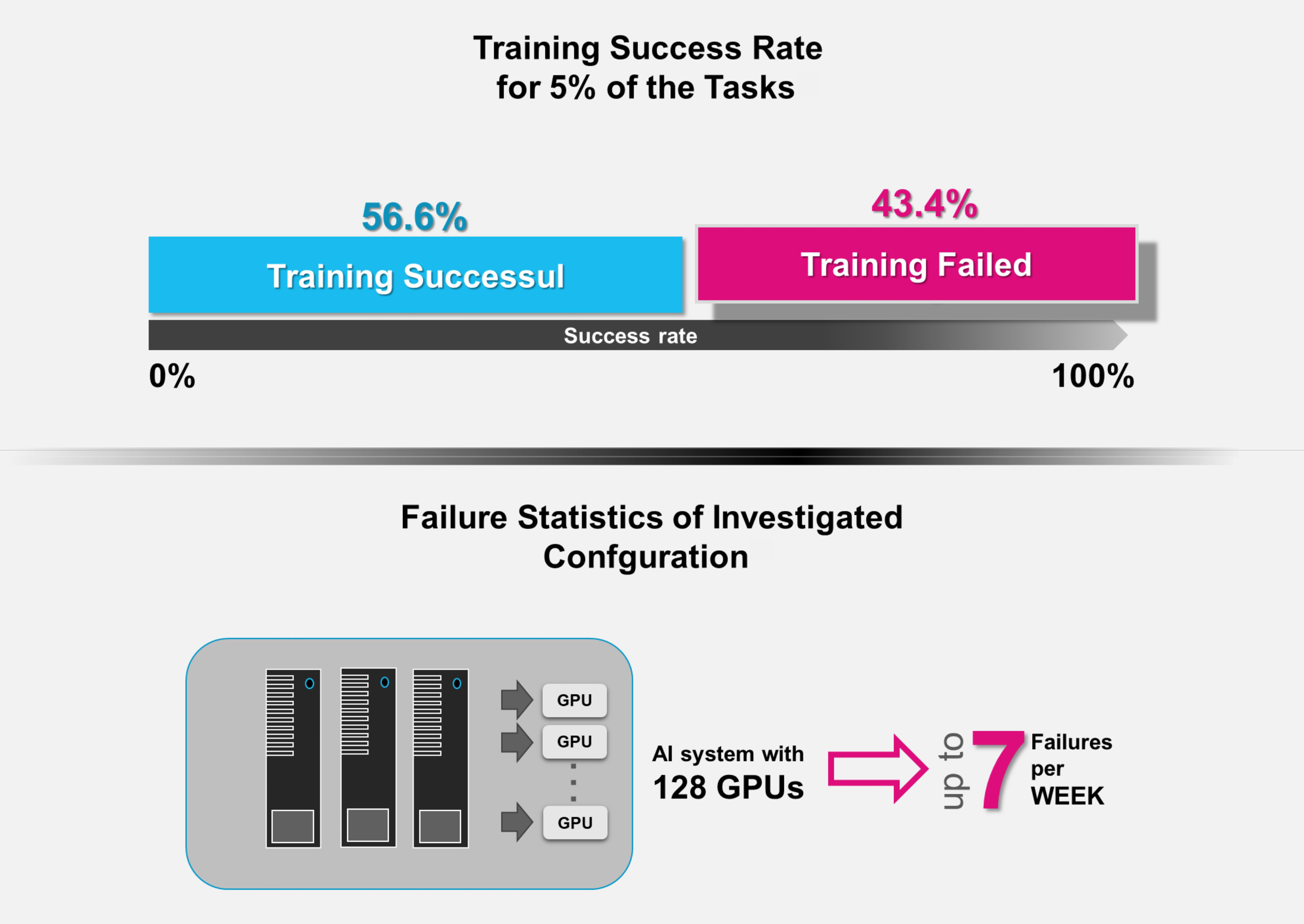
Taux d’échec pour les 5 % des tâches les plus gourmandes en ressources : les systèmes d’IA équipés de 128 GPU peuvent subir jusqu’à sept pannes par semaine
Les points de contrôle sont des instantanés périodiques de l’état du modèle (paramètres, poids, états de l’optimiseur) permettant de rétablir une configuration stable récente. Le contrôle ajoute de la surcharge au temps d’entraînement - moyenne de 12 %, jusqu’à 43 % dans les pires cas. La bande passante d’écriture requise pour le contrôle dépend de la taille du modèle et de la limite de temps autorisée. Par exemple, sauvegarder un modèle de 530 milliards de paramètres (7 420 Go) en 72 secondes nécessite une bande passante d’écriture de 103,1 Go/s pour maintenir la surcharge à 1 %.
Si la bande passante d’écriture est inférieure (par exemple, 10,3 Go/s), la portion de points de contrôle augmente significativement (par exemple, 10 %), réduisant directement le temps disponible pour la formation. Une bande passante d’écriture élevée depuis le stockage est essentielle pour un contrôle efficace et maximiser le temps d’entraînement. La protection des données d’entraînement est vitale du fait de leur valeur.
A ce niveau, le chiffrement matériel est plus efficace que le chiffrement logiciel. Les disques à chiffrement automatique (SED) protègent les données stockées en les chiffrant au sein du disque SSD, empêchant ainsi l’accès sur d’autres systèmes sans mot de passe. Les disques SSD à chiffrement automatique KIOXIA respectent la norme Trusted Computing Group (TCG) et effectuent un chiffrement à la volée avec accélération matérielle, sans introduire de latence visible ni de réduction des performances.
Quelques points à analyser pour les disques SSD dans les systèmes d’IA
Les disques SSD à haute capacité actuels offrent des avantages significatifs par rapport aux disques de génération précédente en termes de coût total de possession (TCO) grâce à la consolidation des économies d’énergie, de refroidissement et d’autres économies opérationnelles, ce qui les rend particulièrement adaptés aux solutions de stockage centrées sur l’IA.
Cependant, il est important de reconnaître que le stockage ne représente qu’une petite partie du coût total d’un système d’IA, même s’il peut influencer significativement l’efficacité globale. Par conséquent, contrairement aux systèmes de stockage conventionnels, les décisions concernant le choix des disques SSD doivent être principalement dictées par des exigences techniques et non uniquement par le coût. Les systèmes de stockage IA doivent fournir des performances élevées et constantes avec des latences faibles et prévisibles sous des charges de travail variables afin d’éviter la sous-utilisation du GPU en attendant les données.
Les disques SSD doivent posséder ces capacités, avec des latences constamment faibles et des opérations d’E/S par seconde (IOPS) stables, s’adaptant efficacement aux charges de travail changeantes. Pour le stockage NVMe local près des GPU, le format standard Enterprise and Datacenter (EDSFF) offre un meilleur refroidissement grâce à une hauteur/épaisseur réduite, permettant un meilleur flux d’air vers les GPU.
L’EDSFF procure également une meilleure qualité de signal pour PCIe 5.0 et les interfaces futures comme PCIe 6.0 comparé aux anciens 2,5 pouces. L’EDSFF permet également des enveloppes de puissance plus élevées (jusqu’à 40 W ou 70 W) comparées aux 2,5 pouces (jusqu’à 25 W). Les systèmes GPU modernes intègrent des disques NVMe connectés localement avec la DRAM comme couche haute vitesse pour la mise en cache ou la mise en attente de grands ensembles de données dépassant la capacité de la DRAM.
Cela réduit la nécessité de traverser le réseau, offrant une faible latence et des avantages en termes de performance. NVIDIA GPUDirect Storage (GDS) permet des transferts directs de données depuis le stockage NVMe local ou distant vers la mémoire GPU, améliorant ainsi les performances d’E/S et réduisant la latence de par l’élimination du “tampon de rebond” sur le chemin des données.
Les disques SSD avancés sont essentiels dans les centres de données d’IA modernes pour maintenir les GPU saturés et atteindre une grande efficacité. Les lecteurs PCIe 5.0 de KIOXIA, tels que la série CM7 à double port haute performance et les séries CD8P et XD8 à un port, constituent une excellente base pour l’infrastructure de stockage de données IA.
Ils sont conçus pour répondre aux exigences des systèmes d’IA à toutes les étapes de l’ingestion, de la préparation, de l’entraînement et de l’inférence des données, permettant ainsi aux centres de données de se concentrer sur les applications d’IA en toute confiance dans les disques SSD, qui constituent un composant central robuste et fiable.
(*) Un embedding ou incorporation en français est une représentation vectorielle numérique d'éléments comme des parties de texte ou de paroles, utilisée dans les modèles d'IA générative
(**) Understanding Data Storage and Ingestion for Large-Scale Deep Recommendation Model Training, plateforme arXiv, Mark Zhao et. al., 22 avril 2022
(***) Unicron : Economizing Self-Healing LLM Training at Scale, Alibaba Group, Nanjing University, Tao He, Xue Li, Zhibin Wang, Kun Qian, Jingbo Xu, Wenyuan Yu , Jingren Zhou, 30 décembre 2023.





